
The Dimension Reduction Cliff
Smaller vectors, different results. How much drift can your use case tolerate?

OpenAI lets you shrink text-embedding-3-small vectors from 1536 dimensions down to whatever you want. They say you trade off some accuracy for storage savings and I wanted to know how much accuracy, so I ran 50 queries against 5,000 embedded listings at 512, 256, 128, and 64 dimensions and compared every top-10 against full size.
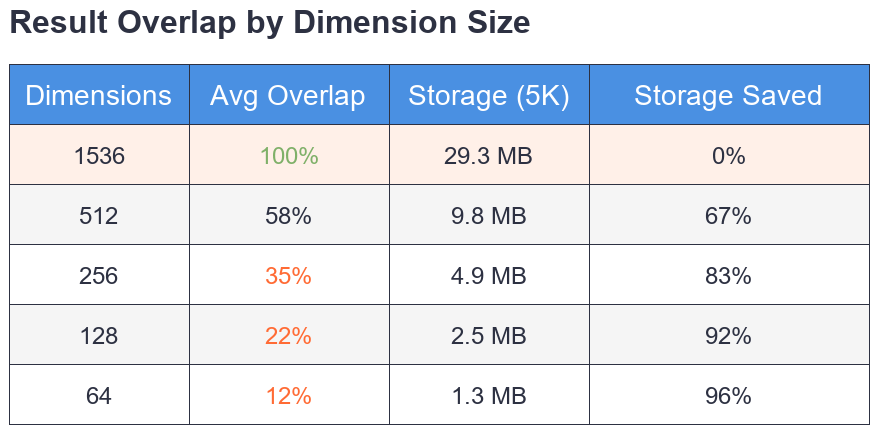
For 512 dimensions 42% of results changed. For 256 dimensions 65% changed. Some queries had zero overlap with the baseline.
I dug into the individual queries like “Spa-like master bathroom” which held up with 6 out of 10 overlap at 512 dimensions. “Butler’s pantry adjacent to kitchen” was a mess though. No butler’s pantries in the 5k rows, so both dimensions gave me chef’s kitchens and breakfast nooks. At 512 dimensions, farmhouse kitchens and wine cellars snuck in0.
Some of that drift is harmless, so with 512 dimensions, I saw plausible results for a lot of queries. The issue is I couldn’t tell ahead of time which queries would hold and which would fall apart.
I think real estate is a bad fit for dimension reduction. The descriptions are too dense, for example across style, amenities, layout, neighborhood, all jammed into one paragraph. You need fine-grained distinctions and those live in the later dimensions.
Fascinating. That 'cliff right at the first step' is so striking.